Enterprises on Azure Cloud and currently following the Event-driven architecture (EDA) need to trigger event based pipelines in Azure Data Factory (ADF). We usually run ADF pipelines on a schedule, but how do we run the pipelines when there are no schedules?
This technical blog gives an overview of the support for event-based triggers in ADF, and how to kickoff event triggered pipelines in Azure Data Factory. The process depends on Azure Event Grid, so ensure that your subscription is registered with the Event Grid resource provider.
Let’s consider a typical use case. Today customers have their data integration pipeline which are usually running on a schedule. But sometimes you don’t know if your operations would produce data at a particular schedule. Only once the data is generated, the pipelines are kicked off. So, in this particular use case, customers can now use an event trigger in ADF to kick off their pipelines.
The first event that ADF supports is a file landing in Azure blob. Sometimes you might have some other process, and you may not know where it is located – whether it is running upstream, or IoT devices. So in this case, does that event gets triggered when the blob lands or when the blob finishes the last pipe?
ADF supports different events – blob created, blob deleted. And, ADF supports multiple patterns, such as:
- Specifying a container name
- Specifying a file inside a container
- Specifying a path
Let’s look at how to kick off event-driven pipelines.
Quick Demo
- Create a Data Factory
- Launch ADF Visual Tools
- Here, we have a pipeline where we are copying data from Azure blob to SQL DW
- This pipeline has a copy activity, and the source of the pipeline is an Azure blob
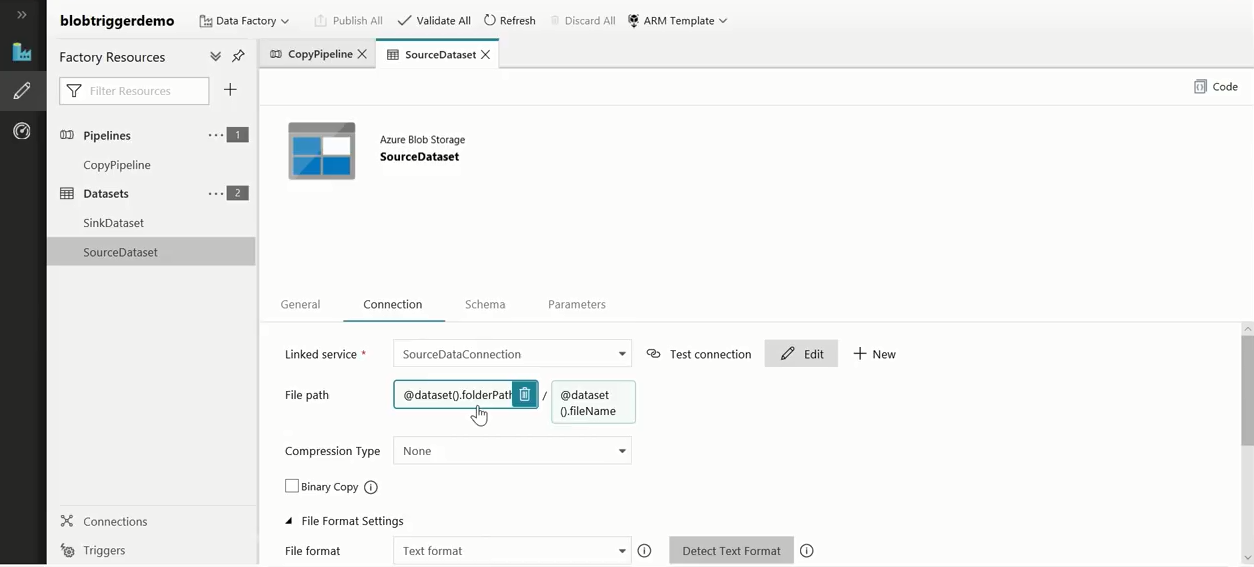
Setting the source and sink of the pipeline
The pipeline has a source, and in this case the source is an Azure blob storage. There may be multiple connections in the pipeline, and we need to parameterize a specific file path. The necessary parameters to the file path are passed when the pipeline runs. These parameter values are specified to the file path, by the event based trigger.
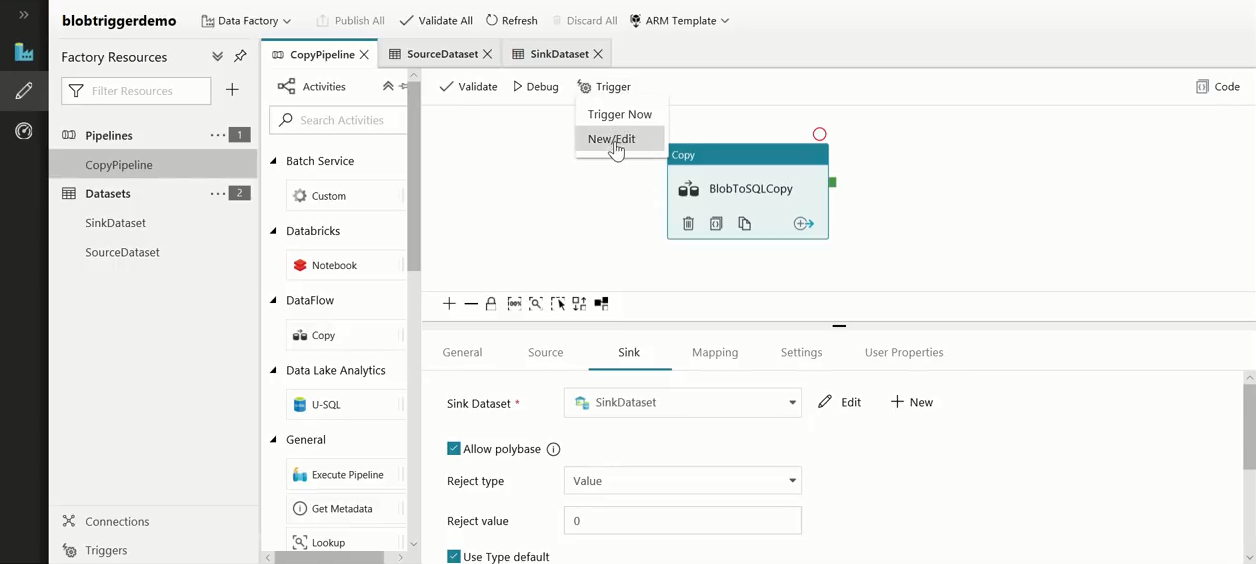
The sink of the pipeline here is a SQL DW dataset, and we would be copying some customer information from the Azure blob to the SQL DW. Going to the pipeline:
- Click ‘Trigger’
- Then, click ‘New/Edit’
Setting the trigger conditions
Here, the Blob path begins with property is set to /source/ and the following conditions are set:
- If there is a container named /source/ and
- If any file drops in that container
Then, the pipeline would be kicked off.
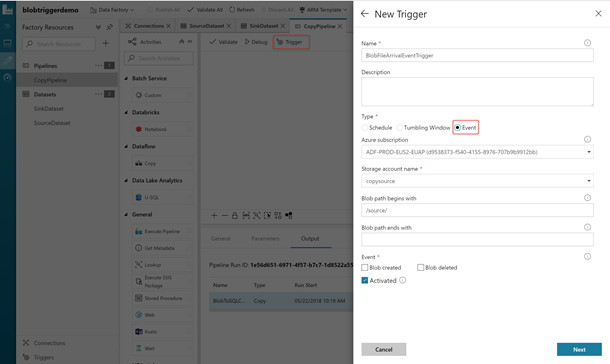
You can kick off a pipeline on two events:
- Blob Creation
- Blob Deletion
Map trigger properties to pipeline parameters
Here, we need to define 2 variables folderPath and fileName which the event-based trigger supports. Whenever the trigger runs, it can pass the folderPath and fileName values for the blob location.
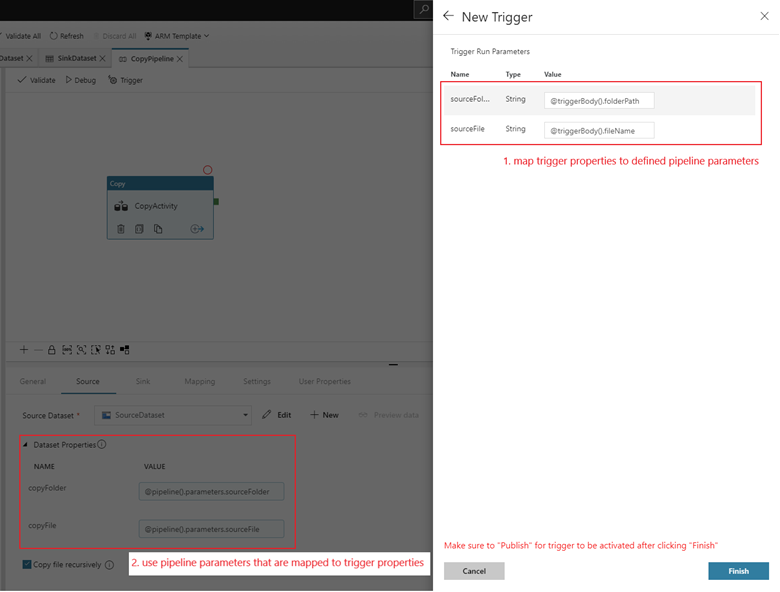
Once the trigger is added and activated:
- Go to the Storage Account
- Copy the required data file (a CSV file for example) into the source container
- Then, go back to ADF -> Monitoring tab
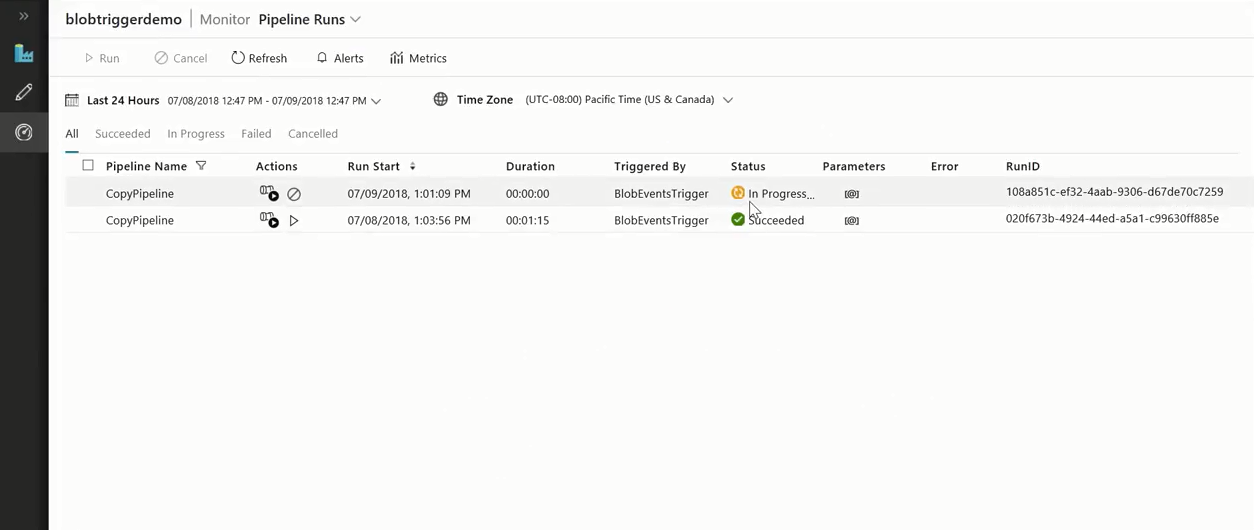
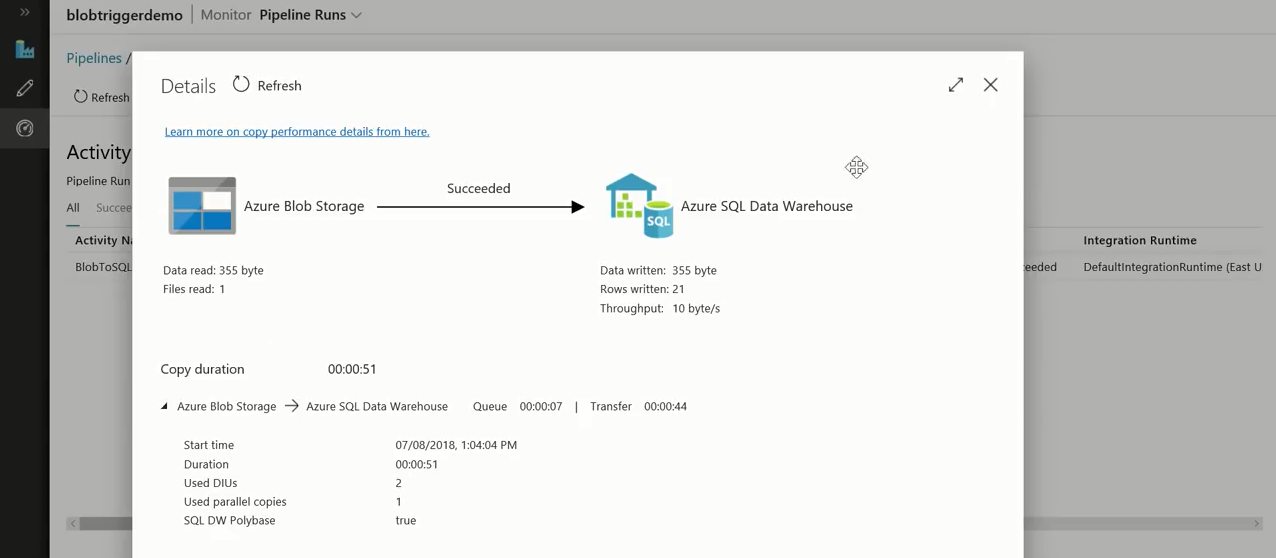
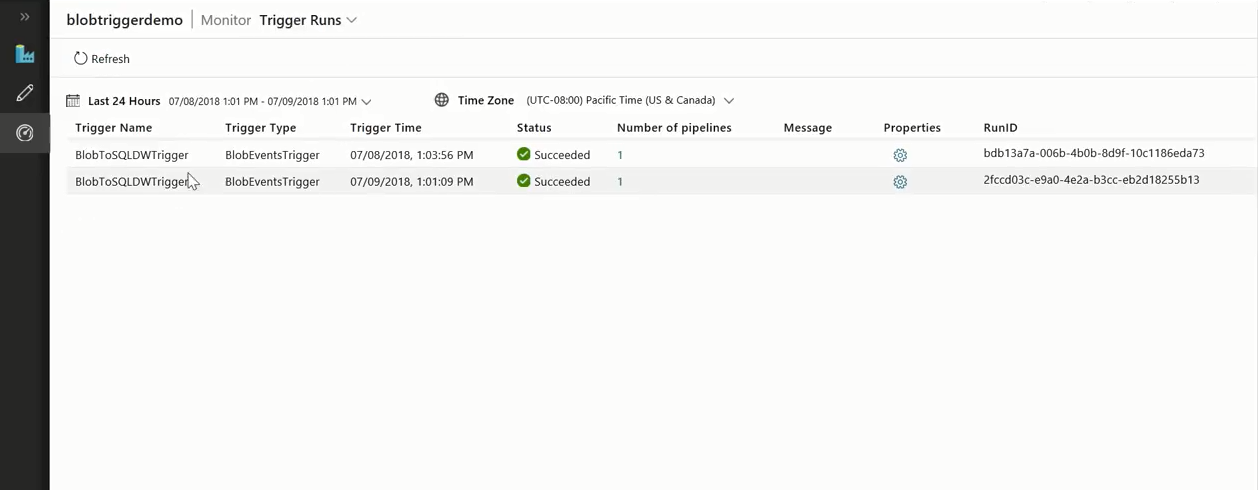
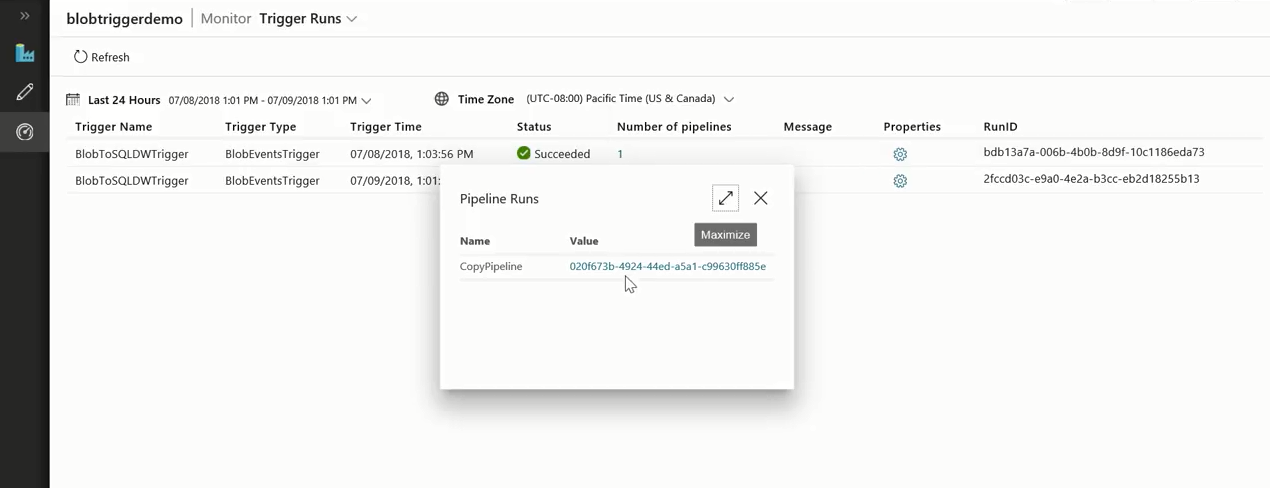
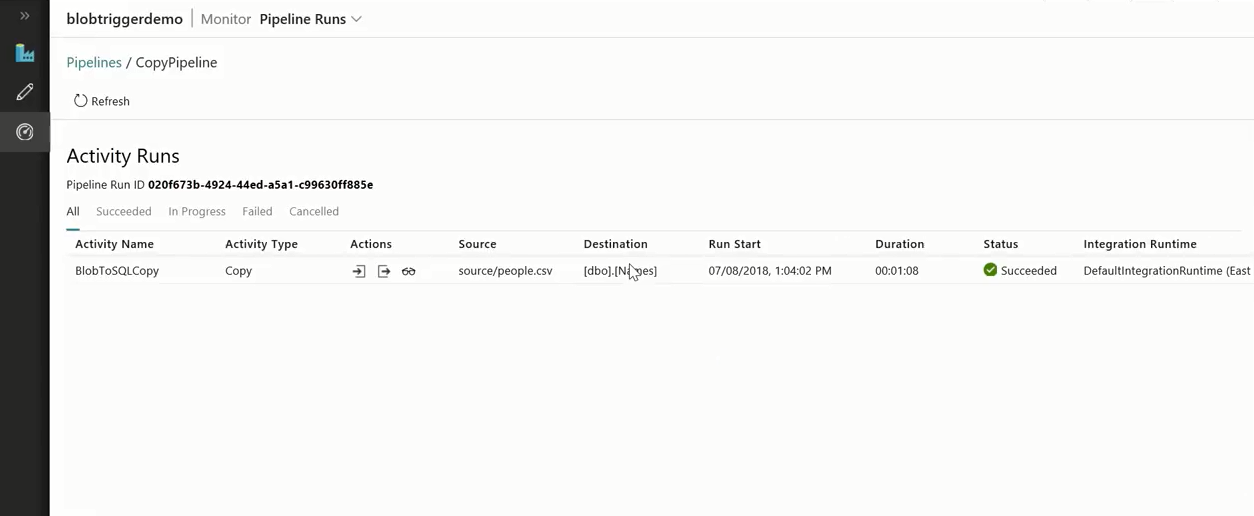
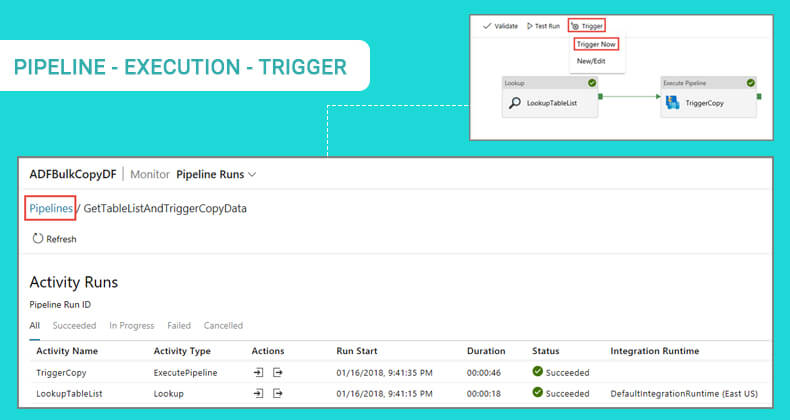
Now, we can observe that a pipeline is running since the file was dropped. This way customers can run event-triggered pipelines.
Once the pipeline run is complete, you can view the pipeline execution details, and the specific trigger run details.